
For my work, I had a 15 mins slot to talk about how Terraform and Ansible can work together to achieve better efficiencies in managing Multi/Hybrid cloud environment.
Due to the time constraints there was a lot of information that was cramped in.
So I decided to write a blog with more details, so people can understand further.
We all understand Terraform and Ansible are both powerful and great tools in Automation with strength and foundations in different areas.
- Terraform – State management
- Ansible – Procedural desired State achievement
With the above, we all should agree on the fact that using the right tool at the right place would help us make our life easier. This is where my thought process of integrating Terraform and Ansible came from.
“What if I could totally use Terraform for setting up and maintaining the system, and then use ansible to add those magical finishing touches to the system and application configurations? How awesome would that be?”
This article would give us a hint on the first step of the integration, Terraform & Ansible integration using Terraform Ansible Provider and I hope to write a few more articles to cover more advanced methods.
Start of this year, Red Hat and its partner team have created “Terraform Ansible Provider”.
– Provider LINK
– Git link
This provider enables a Terraform practitioner 4 specific capabilities:
1. Inventory build – Host variables – host vars parsed from Terraform provisioning process and terraform Statefile.
2. Inventory build – Group variables – group vars parsed from Terraform provisioning process and terraform Statefile.
3. Access to the Ansible vault
4. Execution of an Ansible playbook – assuming the ansible commands, collections and playbooks are available in the provisioned system.
So now let’s get started.
Question:
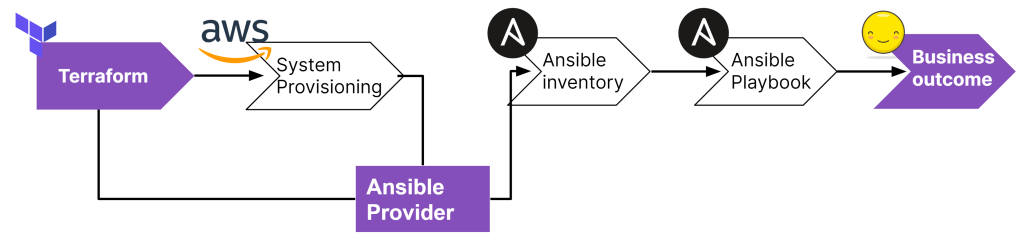
How would I let Ansible know about the system information that Terraform just built?

Simple Answer: By utilising Terraform Ansible Provider. – Github repository
TELL ME MORE!!!!
Detailed answer: Let’s step you through this step by step.
Below is a simple step-by-step example of:
1. Terraform – Build an EC2 instance with certain parameters, especially a EC2 “Owner” tag
2. Terraform – build an ansible inventory with a host section with extra variables that use “Owner” tag from above.
3. Ansible – To finalise the configuration of the system
– Install HTTPD
– Configure index.html using EC2’s “Owner” tag from terraform variable
– Enable/Restart HTTPD service
– Enable/Configure/Restart Firewalld
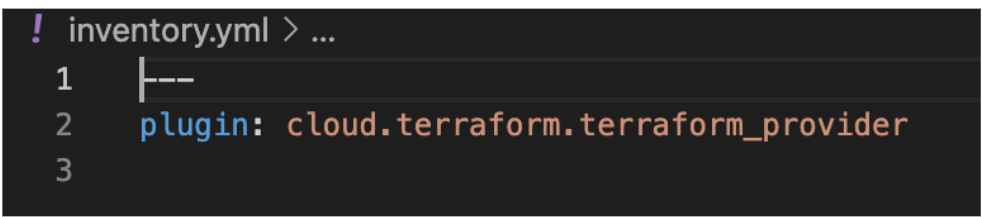
N.B In between the step 2 and step 3, ansible inventory will utilise the “Terraform” inventory plugin to dynamically obtain inventory details from Terraform.
Terraform Ansible Provider is the very first step of the integration between Terraform and Ansible and its CLI and OpenSource Tools centric.
- Pre-requisites/Assumptions:
1. you are using a client system that can have Terraform and Ansible installed
2. Terraform installed with terraform version > 0.13+
3. Ansible installed the latest version
4. Ansible collections are installed
– community.general collection – 7.1.0 or above
5. AWS credentials are already configured within the system
- Prep Terraform files
- provider.tf
- main.tf
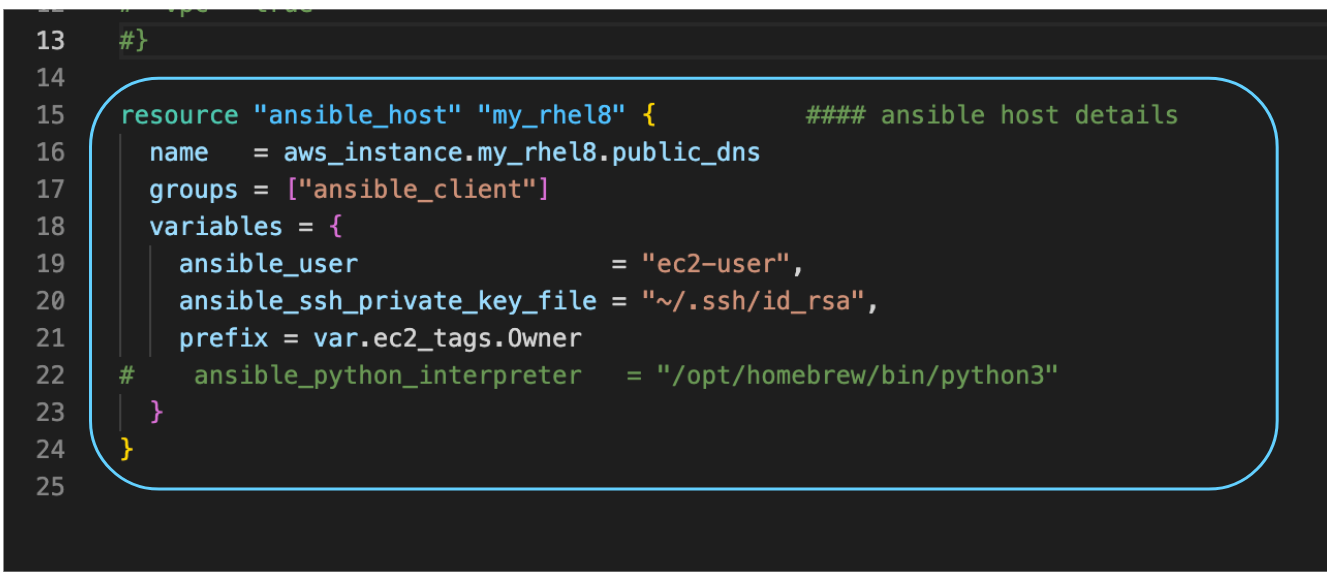
- provider.tf
- Prep ansible inventory file
- Run Terraform to provision the EC2 instance
$ terraform plan
$ terraform apply - Check ansible inventory file + inventory details

inventory.yml
- Run ansible playbook
$ ansible-playbook -i inventory.yml hashicat.yml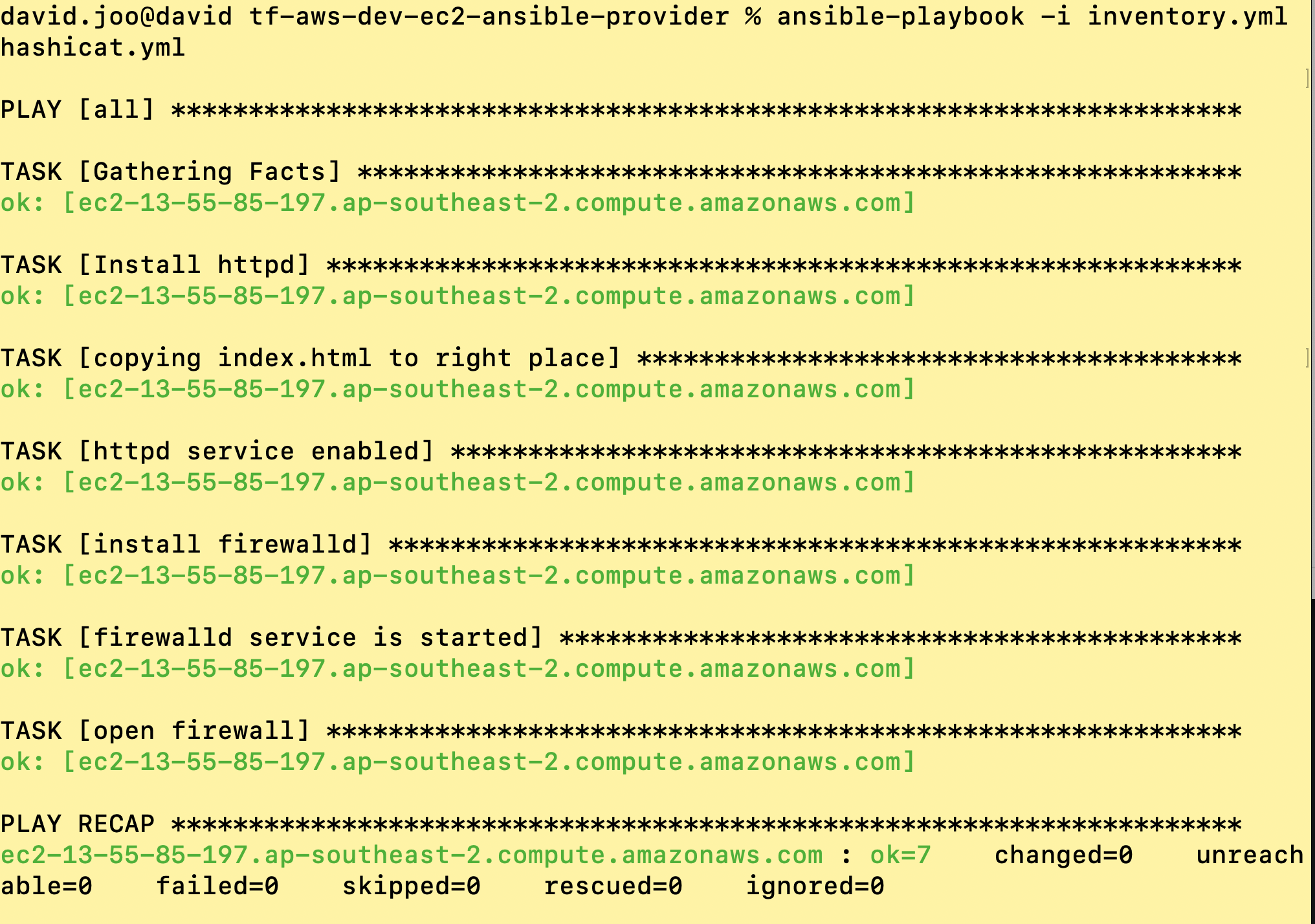
- Check the result


Summary:
This article covered a simple demo utilising Terraform ansible provider to pass system information from terraform to Ansible. This is a basic but a good example on how a practitioner can integrate Terraform and Ansible to achieve better efficiencies by taking better of both worlds.
If you have more questions, please don’t hesitate to contact me on
david.joo (at) hashicorp.com



